
Last month EUDAT’s roving reporter interviewed the product manager for EUDAT’s B2SHARE service, Carl Johan Håkansson (PDC Center for High Performance Computing, KTH Royal Institute of Technology, Stockholm) to discover what B2SHARE is all about. If you missed that introduction to B2SHARE, you can read it on the EUDAT website. This month we turn to Carl Johan again, this time to get an overview of how to use B2SHARE for storing research data. Although the B2SHARE interface is quite simple to use, this overview may be useful for anyone who is unfamiliar with storing data on large computer systems. Carl Johan also introduces us to the concept of metadata and highlights the fact that, if we want our research data to be readily accessible to others, we must take responsibility for creating good quality metadata here and now when we store our data!
Good afternoon, Carl Johan. Last month, you explained that B2SHARE lets European researchers make their research data publicly available just by using a normal web browser. If I remember correctly, you mentioned that people need only go to the B2SHARE website (https://b2share.eudat.eu) and log in and then they can start searching for or storing data.
Yes, that’s right, although in actual fact, you don’t even need to log in to search for data with B2SHARE. Anyone can start searching the available data just from the B2SHARE website, but if you want to store data with B2SHARE, then you do need to register as a B2SHARE user (if you haven’t already done so) and log in to the service.
Thanks for that clarification, Carl Johan. Now, let’s suppose I’m hypothetically a medical researcher who has been trying to find out if there is a connection between, say, levels of active thyroid hormone in the cells of the body and chronic fatigue syndrome. I’ve just completed my research project, so I have quite a few Excel files on my laptop containing my initial data and also some files with the results of my statistical calculations. I’ve completed my analysis of the results, drawn my conclusions and now I’m ready to publish all the data that I used so other researchers can check my work or use my initial data for some new research of their own. As I have not used B2SHARE previously, I’ve opened my web browser, registered at the B2SHARE website and logged in. What do I do next in order to store and publish these different data files?
Well, it is actually so easy that you hardly need an explanation. You simply choose the file or files to be stored in B2SHARE – this can either be done by dragging and dropping, or by selecting the files via a file browser. Please note that when you store data using B2SHARE you can store either a single file, or you can store a group of files that will be kept together. In your case, you have several files that should be kept together, so you will need to select all of those files from your laptop. Once you have chosen those files, you then select the type of metadata set that will describe your data and enter the relevant metadata information.
Hang on a moment, Carl Johan. Before you go further, would you explain what metadata is, for those of us who aren’t familiar with that term?
Yes, sure, I was just about to get to that as metadata is absolutely vital. What we need to remember here is that the whole reason for storing research data and making it publicly available is so that other people can find that data and use it – either to verify previous research or for completely new research. And we want anyone who might be even vaguely interested in your data to be able to find it (and understand what it is about) easily. But how can someone who hasn’t heard of you or your research actually find your data? This is where metadata comes in – metadata is essentially information stored along with your data that describes what your data is about and what it contains.
When someone else searches for data in B2SHARE, all the stored metadata, including yours, will be checked for matches with whatever is specified in the search. So it is important to make sure that your metadata describes the “when, where, what, why, who and how “of your research data. When you are creating that metadata, it can be useful to include information describing your research topic generally – saying what you were trying to find out or testing for. The better and more comprehensive your descriptions, the more chance anyone who is searching for data like yours (or for data related to research like yours) has of actually finding your data.
To understand what I mean, think about when you try to search for something on the internet. You’ll search for particular words or expressions that describe what you want to find, and I’m sure you know the frustration of having nothing useful come up in page after page of Google search results, and then racking your brain for other ways to describe what you are searching for until you finally think of something that actually leads you to the information you want. Now, if the people who originally created the page with the information that you wanted had used more obvious terminology to describe what was on that page, then it would have been much easier for you to think of words that would mean the Google search would find that page for you.
Yes, I know that feeling. Going by my experiences with web searches, isn’t it a problem as there are often lots of different ways of saying the same thing? How can researchers be sure that the terms they choose to describe their data will allow everyone else to find their data? For example, going back to my hypothetical research on chronic fatigue, when I store my files in B2SHARE, how do I enter metadata that means all the people who sometimes use the term ME (myalgic encephalomyelitis) as a synonym for chronic fatigue syndrome will be able to find my data?
Well, the reality is that we can never be completely sure that the terms we use to describe our data will mean that everyone can find it. This highlights how important it is for people to enter clear, correct and comprehensive metadata. Going back to your example about chronic fatigue and ME, you can see that when there are multiple ways of saying the same thing, it is also very useful to include synonyms (that is, words or phrases with the same meaning) so that it doesn’t matter which of those expressions the searcher enters when trying to find data. Thus your best bet is to simply include myalgic encephalomyelitis and chronic fatigue syndrome, and their abbreviations, ME and CFS, in the metadata.
Since researchers tend to use jargon and terminology that is specific to their area, it is helpful to include some information in simple everyday language too, and, where possible, to give both common names and more formal scientific terms. In a way, that is what you are doing by including both myalgic encephalomyelitis and chronic fatigue syndrome. This makes it more likely that people from outside your area will be able to find and use your data. Remember that you are aiming to create metadata that will be understandable decades or perhaps even centuries into the future.
If everyone takes responsibility for entering good quality metadata, then that makes it possible (and hopefully even easy) for other researchers to find data about a particular topic – and to understand the value of the data rather than dismissing it as irrelevant. This in turn enables us to use data in new ways, for example by combining data from completely different research projects to look into a different topic, which is one of the reasons that we are trying to make all this research data available globally and in the long-term. For example, with your hypothetical chronic fatigue research, if you include the geographical location of each of the patients who were studied and the dates when they started showing symptoms (even if you didn’t use that information yourself), then another researcher who is, say, looking for a connection between chronic fatigue and viruses could cross-reference those patients with dates and areas where there were outbreaks of specific viruses.
So, coming back to your question about making sure other people can find data, there are no guarantees and thus ultimately you, as the person storing the data, need to take full responsibility for entering appropriate metadata. The good news though is that B2SHARE does offer you help with that in the form of metadata sets.
Ah, then I have to ask: what is a metadata set?
Well, data from a particular research area, for example, biochemistry, tends to share characteristics that may not be relevant in other research areas, such as linguistics or fluid dynamics. So EUDAT has been working with various research communities across Europe to establish sets of metadata information, which include the types of information that are frequently useful for describing data in each community’s research area.
You can think of metadata sets as useful reminders of the main pieces of information that you should include when storing data related to a particular research field.
Ok, so if I’m entering data about seismology, I select a seismology or earth sciences metadata set, but if I’m entering linguistics information, then I select a linguistics metadata set?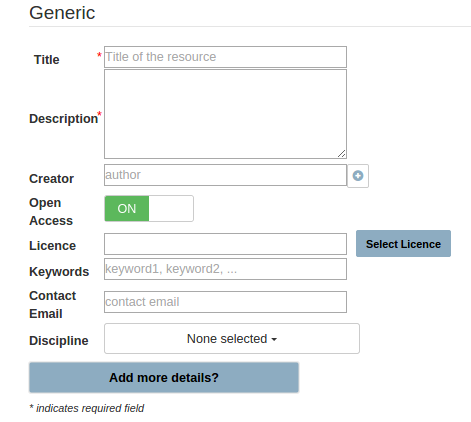 Generic metadata fieldsYes, that’s right. And if you need to enter data from an area for which there is currently no specific metadata set in B2SHARE, then we also provide a general or “generic” metadata set that can be used for any data.
Generic metadata fieldsYes, that’s right. And if you need to enter data from an area for which there is currently no specific metadata set in B2SHARE, then we also provide a general or “generic” metadata set that can be used for any data.
Ok, so to summarise: If I want to store data in B2SHARE, I choose the files that I want to store, then I select the metadata set that is most relevant for my data – and if nothing else fits, I choose “generic” metadata – then I enter the metadata…
Yes, and when you are entering your metadata, it is useful to be aware of the concept of licences for data. When you store data so it is available publicly, it is important that you make it clear what other people are allowed to do with your data. The permissions and restrictions that you want on the use of your data are recorded using what are known as licences.
When you have selected your metadata set in B2SHARE, some headings will appear with places, known as fields, where you can enter text or choose information from a drop-down list. (By the way, we use drop-down lists where possible to improve the accuracy of metadata and also to save you time on typing.) There will also be a “Select licence” button. When you click on that, a new window will open up and you will be asked questions that guide you through the process of selecting an appropriate licence for your data.
Thanks, Carl Johan. That all sounds fairly straightforward. Login, choose the files, and then add comprehensive accurate metadata describing my data and research, and make sure to select a license to say what other people can do with my data?
Yes, precisely, and please remember that entering good quality metadata is absolutely crucial. If we want research data to be useful in the future, we have to make time here and now to enter clear and comprehensive metadata.