
This month we caught up with Marcello Maggi, a senior researcher at the Istituto Nazionale di Fisica Nucleare (National Nuclear Physics Institute, or INFN) in Italy and author of about 750 scientific papers on high-energy physics. Marcello is part of the ALEPH Collaboration, a partnership that set up one of the four experiments carried out on the Large Electron Positron (LEP) collider at CERN, which generated data from 1989 to 2000. After having played a number of key roles in ALEPH, he is now responsible for the ALEPH data-archiving system. He is presently working on the Compact Muon Solenoid (CMS) experiment using the Large Hadron Collider (LHC) at CERN and represents INFN in the Study Group for Data Preservation and Long-Term Analysis in High-Energy Physics (DPHEP), as part of which the collaboration with EUDAT started.
1. Could you tell me a bit about your work? What is the nature of data that comes out of your high-energy physics projects?
I’m a physicist at INFN in Italy. My main interest is in exploring the fundamental constituents of matter, their nature, and the link with space and time, in order to understand the origins of the universe. I work on the experiments conducted at the CERN laboratory in Geneva, Switzerland. These experiments are conducted by scientists from all over the world, meaning that data needs to be shared in order to perform data analysis in a highly collaborative environment. It was not surprising the World Wide Web was invented at CERN.
Physicists are always attracted by complexity: they try to simplify what is observed in nature with few simple laws, unifying seemingly different phenomena in a single framework. The framework to describe the behaviour of the ultimate constituents of the matter is the Standard Model of particle physics. It describes the forces between matter particles in terms of an exchange of carrier particles. The Standard Model encapsulates three of the fundamental forces in nature: the strong force, the weak force, and the electromagnetic force. Gravity is left aside. An important ingredient is the presence of the Higgs field, which is responsible for creating all particle masses. Higgs particles were sought for a long time and were recently discovered at the LHC in the new experiment I’m working on.
If you’re interested in finding out more about the Standard Model, you can watch CERN’s introductory video on YouTube and read more on the CERN website.
2. Could you explain what the ALEPH experiment was?
ALEPH was a very challenging project. The experiment was installed on the LEP collider at CERN. The main goals were to explore the Standard Model of elementary particles, to search for the Higgs particle and to search for new physics beyond this. One of the main results was the determination of the number of families of light neutrinos, which are electrically neutral, weakly interacting subatomic particles. ALEPH started recording events in July 1989. LEP operated at around 91 gigaelectronvolts (GeV), the predicted optimum energy for the formation of the Z particle, which, along with the W bosons, is one of the elementary particles that mediate the weak interaction in the Standard Model. From 1995 to 2000 the accelerator operated at energies up to 200 GeV, above the threshold for producing pairs of W particles. Thanks to these data, the electroweak force, mediated by the Z and W particles, is understood with extreme precision. ALEPH was conceived and led for long time by Jack Steinberger (second from left in the photo), who was awarded the Nobel Prize in 1988 for the discovery of the muon neutrino.

A typical event in ALEPH as a result of the collision between the electron and positron is shown in the image below: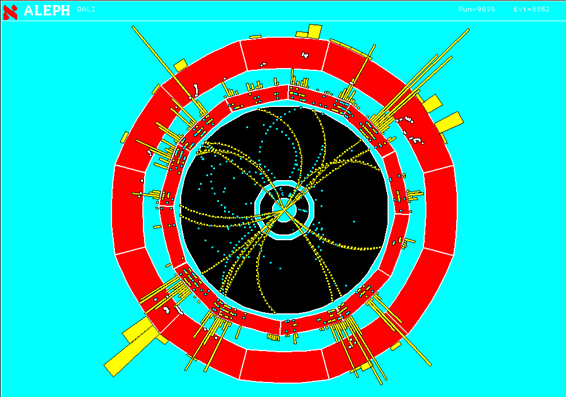
3. Why is it so crucial that data from the ALEPH experiment and other high-energy physics projects be preserved and shared?
The data taken, consisting of millions of events recorded by the ALEPH detector, allowed precision tests of the electroweak Standard Model to be undertaken. Though experiments are theoretically reproducible, the cost of particle accelerators, infrastructures and experiments makes the data produced simply unique. Though many results are published, new advances in physics and new theoretical models and predictions can be tested on these data. Indeed a good number of data analyses are ongoing, which still represent important contributions in High-Energy Physics (HEP). The recognition of the importance of long-term data preservation in high energy by the community led to the creation of DPHEP by the International Committee for Future Accelerators (ICFA). Recently DPHEP, following the recommendations of ICFA, became a project with an increasing number of international partners.
4. Why did you decide to work with EUDAT?
We discussed the issue within the DPHEP project, and it was a longstanding idea of the project leader, Jamie Shiers from CERN, to start using EUDAT services. With my INFN colleague Tommaso Boccalli, we participated in the EUDAT competitive call for collaboration projects. In fact, HEP communities already have an advanced data e-infrastructure, which is tailored to the needs of each of the HEP partnerships. What it is missing is the integration with a data infrastructure focused on a single scientist who needs a greatly simplified way of accessing the data. In my opinion, EUDAT now offers this possibility. It was important to establish how EUDAT could connect to and interoperate with community driven data e-infrastructure to steward data to a larger community of scientists when there was no single organisation behind to deal with the complexity of data management.
5. What EUDAT services do you use? What sort of data do you use the services for?
In the beginning the idea was just to use the B2STAGE service through CINECA. The idea was not only to have a repository for the ALEPH data but also to enrich our metadata schema with the Persistent Identifier, which would allow the data to be found more easily at a later date. After the ingestion period we were able to bring back data to our computing centres, which are European Grid Infrastructure-enabled sites, to carry out data analysis. This was a major achievement in which the data and computing e-infrastructure operated together and it prompted us to realise the importance of a simplified data discovery system. B2FIND meets this need pretty well.
With the help of Sünje Dallmeier-Tiessen and Laura Rueda from the Scientific Information Service of CERN, we succeeded in describing ALEPH data with a Machine-Readable Cataloguing Extensible Markup Language (MarcXML) standard. After developing a dedicated digital library using CERN’s INVENIO technology, we started interoperating with B2FIND, ingesting ALEPH metadata via an Open Archives Initiative Protocol Metadata Harvesting (OAI-PHM) endpoint, a nice example of service interoperation. The final step was to build a virtual environment in which B2STAGE and B2FIND were closely integrated. After a period of development of B2STAGE and B2FIND components, the ALEPH Virtual machine was able to open a virtual EUDAT service with B2STAGE and B2FIND functionalities used in a real data- analytics workflow.
6. What requirements do you have, for example in terms of metadata and being able to find the data at a later date? What level of metadata detail is required for the data which you aim to share?
Metadata used in ALEPH, and in HEP in general, are complicated, since the data discovery within the multitude of datasets can be very selective and use several nested parameters. It is difficult to match metadata schema with simple standards, such as those used in B2FIND. For example, each of the several thousand files contains data, identified with run numbers, which are generated under different conditions or which come from different ‘event generators’: computer programs that model the physics processes that occur in the collisions in high-energy physics experiments. The non-homogeneity of the data content can be described using tables like the one shown below.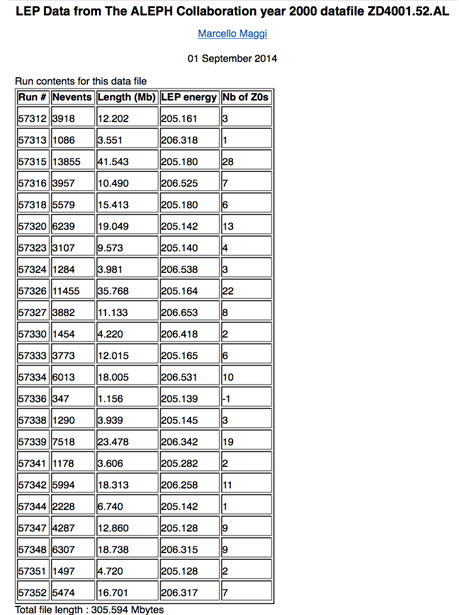
B2FIND assumes general homogeneity of the file content and only general information can be associated to the file. However, this level of complexity can only be used by experts and it requires dedicated systems. B2FIND allows you to use tags, which can be understood by non-experts and should be sufficient for scientists who do not have stringent constraints on data discovery. EUDAT is therefore intended to complement the advanced e-infrastructures already used by HEP physicists.
7. What practical benefits has the collaboration with EUDAT led to? What does EUDAT offer that wouldn’t otherwise be available?
ALEPH data has started to be more visible, and in fact it is now possible to access data not only through the grid but also through the complementary EUDAT mechanism.
8. What additional features do you think should be added to the EUDAT service suite in future?
One possible requirement for large datasets would be to have an additional mechanism to bring data to computing, avoiding the use of local storage, which can be very limited; a data stream mechanism, for instance. I would like to see a B2STREAM which would allow users to perform data analytics without copying the datasets locally.
9. What major challenges do you see ahead in terms of sharing and preserving data? How do you think the requirements of the high-energy physics community might evolve?
Data preservation is not just the mechanism to preserve the datasets; above all, it is the preservation of the knowledge about the data. The major challenge, in my opinion, is to build a framework to interoperate digital libraries, science gateways and data e-infrastructures, powered by a knowledge base with transparent mechanisms for data enrichment and service discovery. EUDAT will play a major role, especially once there is integration of its services with what is, and will be, offered by other e-infrastructures. It is difficult to predict the evolution in HEP since we do not have common standards. But I think that if EUDAT is driven more by individual scientists, rather than just by whole communities, it will maintain its specificity and complementarity independently as it evolves.